Scaling the Mastodon

I was going to write an article for a while now, but there was too much work to do with the latest influx. Together with my co-admin @rixx we run the chaos.social instance. As of writing this, we are one of the biggest and most active instances on the fediverse and one of the oldest mastodon instances, starting mid of April 2017. For the last 5 years everything was simple, one VM with 10 cores, 500GB NVMe SSD Storage and 32GB RAM. This VM did everything from the database to the webserving. Then Musk happened.
The first time we really had to scale our setup was in May 2022 after Musk announced to buy twitter. We rented another server with 4TB NVMe in a RAID1, 16 Cores, 32 Thread, and 128 RAM and migrated the database to this server. And then there was Friday the 27h October 2022 with the headline that Musk finally bought twitter all over the news. With this date, everything became very complicated very quickly. In only two days, the scaling in work load on the fediverse network increased, and most of the larger instances got very slow. We fixed this in only a few days, and this article is a summary about what we did until now. I will keep it up to date with future changes.
Notice: This article is highly assuming that you already know what you are doing as an admin. I will omit plenty of details and only mention the most import parts. Writing a whole tutorial on how everything works would be a multi article series, or actually writing a book.
The current state:
Currently, our setup consists of four dedicated servers:
- 1x 6 cores, 12 threads, 64GB RAM, 1TB NVMe RAID1 (This is the system we started at)
- 2x 16 cores, 32 threads, 128GB RAM, 4TB NVMe RAID1
- 1x 6 cores, 12 threads, 64GB RAM, 30TB HDD RAID10
On these servers we have the following VMs:
- Main VM: Puma (Web Frontend), Redis, sidekiq scheduler queue, streaming API
Resources: 12 cores,46GB64GB42GB RAM, 200GB NVMe storage - Worker VM: Sidekiq Workers
Resources: 10 cores,16GB32GB RAM, 100GB NVMe - DB VM: Postgres
Resources: 10 cores, 46GB RAM, 200GB NVMe - Media Storage VM: Minio S3
Resources: 8 cores, 16GB RAM, 1TB NVMe (CPU and RAM highly oversized, 1GB RAM used) - Backups server for disaster recovery with Proxmox Backup Server
Resources: 6 cores, 12 threads, 64GB RAM, 30TB HDD RAID10
Postgres
Postgres is the first service I would recommend moving to an own system, if tuning everything locally isn’t working out anymore. I would also recommend investing in the fastest possible storage here because the database speed is the bottleneck for the entire instance. We’ve done the migration to an own system in May, when the first massive influx of new people occurred.
As you can read above, our DB VM has a lot of RAM to cache things and speed it up in general. But RAM isn’t everything, and the DB will consume what you provide. I’m quite convinced that things will also scale with much less resources, but if you have them, why don’t use them. For our setup, the 10 cores of the system are not too much consumed, and we could go with four for now.
To find good values to start with, we’ve used the great tool pgtune. But beware to enter all your RAM there. We run out of memory once after dedicating too much RAM to postgres. Currently, we’ve configured postgres to use a maximum of 36GB RAM and added another 10GB for everything else as spare.
We also configured our setup to currently serve up to 700 concurrent connections to the DB and this runs really smooth. The only thing to mention is you really need to push up the maximum number of open files quite high. We currently have 350k configured, with 250k used in peak and an average of 180k. You can do this in your /etc/sysctl.cfg with fs.file-max = 350000. Reload with sysctl -p /etc/sysctl.conf.
To keep your setup small, use PG Bouncer.
PG Bouncer
We currently don’t use it, but we plan to change that in the following weeks. I will update the article after the change.
Redis
We are still running good with the Debian defaults, but if you like, you can run redis on an own system, and you can split it for caching and everything persistent. You could also separate mastodon and sidekiq redis, but this shouldn’t be needed if you don’t run up to > 100k users. The options for this are: SIDEKIQ_REDIS_URL, CACHE_REDIS_URL and just REDIS_URL.
Sidekiq
You can scale your sidekiq workers easily as far as you only want to run them on the local system. If you wish to add more workers on a remote host, things will get more complicated. But let’s start with some context.
Sidekiq is the queue manager, managing all the little tasks you do within mastodon. It handles local and remote posts, it handles link previews, and even liking a toot is a task that is handled by sidekiq. That’s the reason things got slow very fast in the last few weeks after so many new users joining.
For mastodon, there are six different queues:
- The
default queuecontains everything local. This means it is the most important queue and shouldn’t have a high latency. At the same time, it’s the queue which needs the most workers. - The
push queueis handling sending local posts to the instances of your remote followers. - The new
ingress queueis the opposite and handles the toots from users on other instances you follow. - The
pull queueisn’t that critical, as it loads link previews and the like from remote servers. - The
mailers queuehandles registration and password reset mails and everything else related to mails. - The
scheduler queuehandles repeated tasks like cron. For example, it handles the cache or the retention of sessions.
The scheduler queue may only run within one process. The best approach would be to define your own systemd service for it. We are configuring a pool of 25 connections and 10 threads for the service.
For the other queues, there are two good options: The first one is a service unit for every queue, but I would recommend adding all other queues too after the main queue for this unit. This way, if the primary queue is empty, the next one is used. Example: bundle exec sidekiq -c 60 -q default -q ingress -q push -q pull -q mailers. This example is also the best option for simple setups, as it prefers local performance over remote performance.
The second option is to add a priority. This way you could tell, for example, that for one task in the ingress queue, it should process two on the default queue. Example: bundle exec sidekiq -c 60 -q default,4 -q ingress,2 -q push,2 -q pull -q mailers.
Currently, we use the simple setup with DB_POOL=90 and 60 worker threads (-c 60) and start specialized workers on demand if needed. With this, we can run up to 8 workers with 60 threads each on the worker defined above.
If you use the first option, you can also go down to 25ish threads for pull and mailers queue.
If you run the mailers queue on a remote or multiple systems, you need to add a mail server for each or configure a shared mail account in the config. I recommend the latter.
If you want to run remote workers, you require a connection to the redis database and the postgres. Postgres supports TLS and you should use it if you don’t have a protected internal network. Unfortunately, the redis library mastodon is using doesn’t support TLS. We added a wireguard VPN tunnel to the redis server, so the connection is encrypted too.
If you want to spin up multiple workers, you can use a template unit file like this mastodon-sidekiq@.service (note the @) and start up multiple instances of the same service with systemctl start mastodon-sidekiq@{1,2,3,4}.
Oh, and I highly recommend to set RAILS_LOG_LEVEL=errorthe default is info and this logs way too much stuff even warning generated up to 10GB of logs on only one day.
Every remote worker installation needs a full installation of the mastodon code. Remember this while upgrading.
The last point, if you want to use remote workers you require a S3 compatible shared storage.
S3 Minio
First of all, you can migrate your local storage setup to a S3-compatible storage, but it will take time. For us, it took little more than two days to transfer all 2.4 million files we had at the moment of migration.
To use remote sidekiq workers, you require a central storage. You could build something with NFS or the like, but it is not recommended, and it could get you in trouble because of high latency. So please use a S3 compatible storage. I would recommend a self-hosted variant with minio, but there are also countless commercial providers for that. But have a look at their pricing to prevent high bills.
The most complicated things with S3 are the permissions. The following is the config for anonymous access to the bucket (in minio set this in the bucket config). This will limit the access to GetObject for specific files only. This means to request the media file, you need to know the full URL. With this config, object listing is disabled (which is enabled in most read only configs) and this is important to prevent leaking all your media to the world and disclosing media of private accounts or follower only posts.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"*"
]
},
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::mastodon/*"
]
}
]
}
Permissions for the user who is configured in the mastodon config file. This allows all operations to the bucket, but not to other buckets on the same S3 storage.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::mastodon/*",
"arn:aws:s3:::mastodon"
]
}
]
}
After configuring the bucket and user permissions, you need to sync your old files. If you start a new instance, you can skip this part.
You can do the sync with the tools described in the article of cybre.space or the one from Stan.
After the first sync, you switch mastodon to S3 and then re-sync the missing files added during the first round. This will lead to some broken media at the time of the second migration, but that’s not that big of a problem, just be prepared for questions about it.
You may want to proxy and cache the media. This is especially important if you use S3 from a cloud provider to prevent a cost explosion. Furthermore, proxying would keep links consistent in case you change the S3 provider. If you self-host it with minio or something else, this isn’t needed, but strongly recommended to preventing future difficulties. For once, there is a good example for nginx in the mastodon docs.
You can also build everything to allow migration in the background with new media directly uploaded and served to/by S3 and old media, that isn’t migrated yet, served as fallback by the old local storage. For this you need to tune the config linked before. Here is a full example. The important parts are:
# This is the fallback to the local storage
location @fallback {
root /home/mastodon/live/public/system/;
}
# Remove this block
# location / {
# try_files $uri @s3;
# }
# Change location from @s3 to / because we first want to try finding the media in our S3 storage
location / {
# ... lots of other stuff...
proxy_intercept_errors on; # we need to enable error interception to do our fallback
error_page 404 = @fallback; # in case of 404 not found from the S3 storage try to finde the file in the local storge
}
With minio and the proxy example, the config for mastodon looks like this:
S3_ENABLED=true
S3_BUCKET=mastodon
AWS_ACCESS_KEY_ID=<your randome id>
AWS_SECRET_ACCESS_KEY=<your randome secret>
#S3_REGION=de
S3_PROTOCOL=https
S3_ENDPOINT=https://minio.example.com/
# Optional
S3_ALIAS_HOST=assets.example.com
Puma
Until now, we didn’t have to tune puma a lot. Currently, we run puma with WEB_CONCURRENCY=8 and MAX_THREADS=15. Because every thread can handle one request, this means 200 concurrent requests to puma. This is the limit we found to be most effective at the moment. More threads tend to consume more CPU, more processes (WEB_CONCURRENCY) tend to consume more RAM. In our setup, each puma worker process tends to consume up to 2-2.5GB RAM. Thus, 8*2.5GB equals 20GB of needed RAM, and we still need some for redis and everything else on the system.
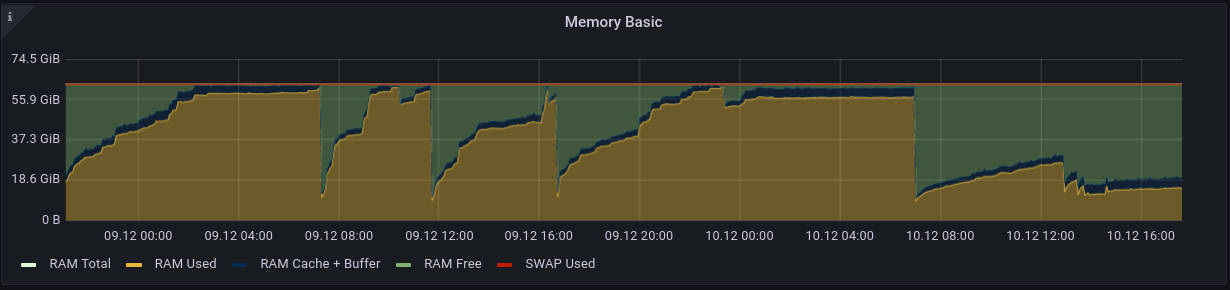
We observed puma consuming all the available RAM regardless of how much memory was available. After some hours, the OOM killer killed the processes. But we could fix it by using the Jemalloc memory allocator. To be sure it is used, add this line to your service file Environment="LD_PRELOAD=libjemalloc.so". This is the option that can be found in the service file in the mastodon repo too. Setting Environment="MALLOC_ARENA_MAX=2" should work too, but is much less efficient. You can find more info on this Heroku changelog post. On Debian you have to install libjemalloc-dev.
If you require, you can move puma to a separate system and install a load balancing nginx proxy before your instances. If you do so, you need to set TRUSTED_PROXY_IP to keep rate-limiting working. If you don’t your load balancer IP will hit the rate limit really fast, rendering your instance unusable.
Streaming-API
The streaming-api is the ugly blackbox of mastodon without good documentation. Even the scaling article from Gargon only says: “increase STREAMING_CLUSTER_NUM if you see not working streaming connections”. Thanks for nothing. Currently, we work well with STREAMING_CLUSTER_NUM=15STREAMING_CLUSTER_NUM=40 without users reporting any problems that sound like broken streaming.
It looks like you should look for something like node[1201554]: ERR! error: sorry, too many clients already in your logs.
Nginx
I would recommend enabling HTTP2 for your instance. Besides this, the first thing you will need to do is increase the number of open files and worker connections. Our current settings are (put them on the beginning of your nginx.cfg):
worker_processes auto;
worker_rlimit_nofile 10000;
events {
worker_connections 4096;
}
Linux
Monitor the number of open files on your systems. We increased it on nearly every system to 150k with fs.file-max = 150000 in your /etc/sysctl.cfg. You can reload the config on the fly with sysctl -p /etc/sysctl.conf.
Traffic
The traffic is hard to calculate because it depends highly on your specific setup and how much traffic is transferred between all your systems. But to give you some evidence, our main VM currently transfers 8TB per month.
Monitoring
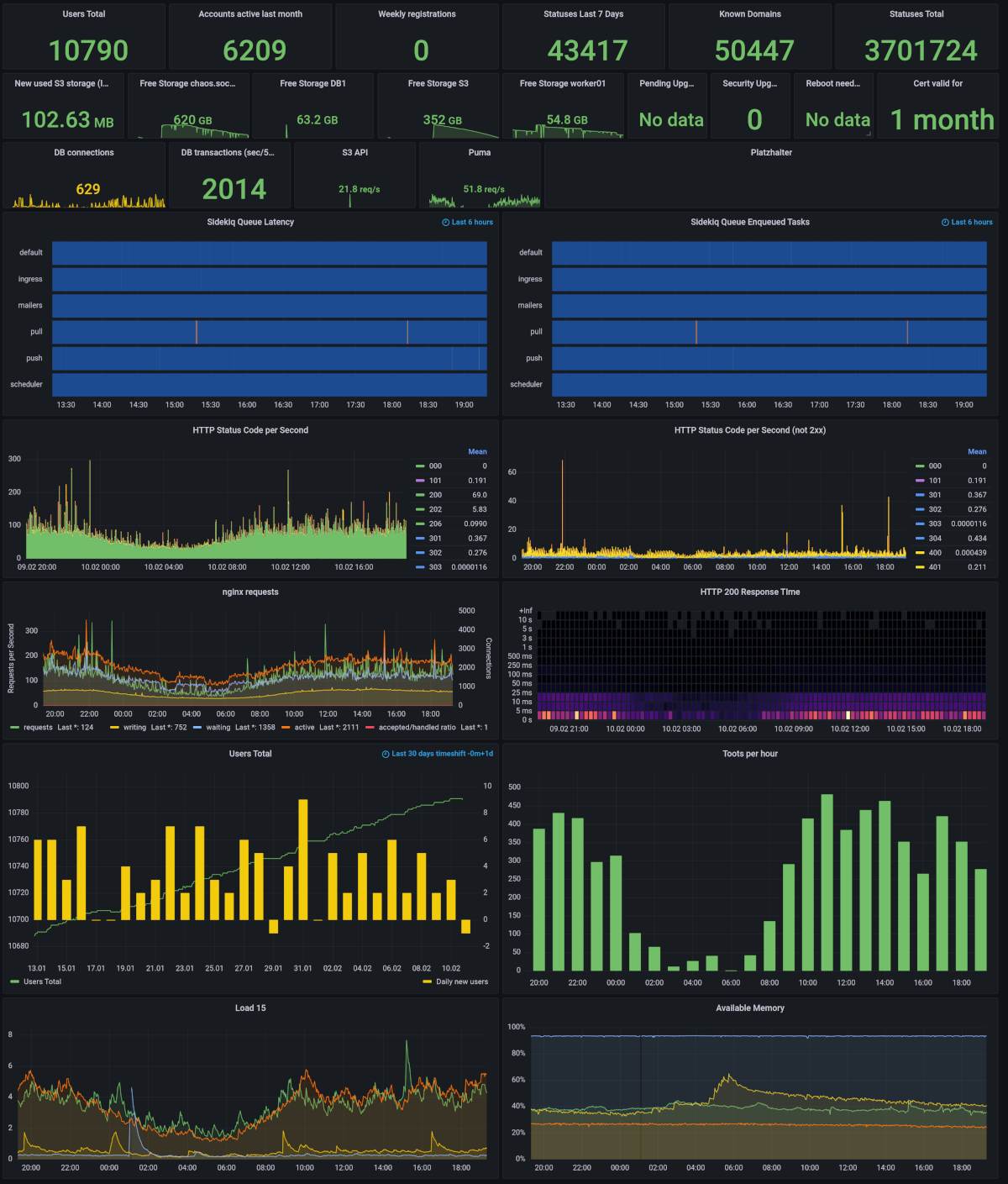
You can easily get prometheus exporters for the system (node_exporter), postgres (postgres_exporter), minio exports their own metrics, and you can also attach a redis exporter. The instrumentation of mastodon itself is not that great and uses statsD. But luckily there is a statsd_exporter you can use to transform the metrics for database query and view timing, redis cache, sidekiq queues and some more. To convert the metrics in statsD format to nice prometheus metrics with labels, you can use the mapping config by IPng Networks. There is also a good article about getting these statistics.
A dashboard can look like this:
The human factor
Running infrastructure for other people comes with a responsibility. But if you know what you’re doing in terms of tech and security and backups, it’s manageable. The real issue is: You’re providing a platform for others, and this means moderation. This isn’t something that is as easy as scaling a server, it’s really hard work. I wouldn’t recommend anyone to run a server with more than a few hundred accounts on their own. Search for a good friend you trust. This also helps with hard decisions, and there will be plenty of them. Don’t scale your instance above 10k accounts or 6 thousand active users if you aren’t more than two. And this is only the value for an instance with a known community. I would only recommend half of that for a normal public server without an existing community. I know it’s a great feeling if people are liking what you build, but it wouldn’t help anyone if you burn out or your instance is going to be a hell because you have not the resources to moderate it properly. There is already this excellent article from my co-admin @rixx about moderating our instance, you can find on his blog. We also plan to add more articles on this important topic in the future. So better subscribe the feed of his blog too. ;)
Questions
I may have forgotten a lot here, so if you have questions, you can write me on mastodon. I will do my best to answer your question and update the article accordingly.
Other resources:
- [1] https://github.com/cybrespace/cybrespace-meta/blob/master/s3.md
- [2] https://stanislas.blog/2018/05/moving-mastodon-media-files-to-wasabi-object-storage/
- [3] https://gist.github.com/Gargron/aa9341a49dc91d5a721019d9e0c9fd11
- [4] https://hazelweakly.me/blog/scaling-mastodon/
- [5] https://softwaremill.com/the-architecture-of-mastodon/